This is the third post in the series "Share your infrastructure"
- Part 1 : The 20,000 foot view
- Part 2 : Our loved tech (hard/soft)ware stack
- Part 3 : SQL Server : lessons learned
App per Schema
First of all, we have a lot of databases, but one very important thing is all our tenant databases have the exact same schema, all the time. When we change the schema, we change it on all the clusters, production, or non-production ones.
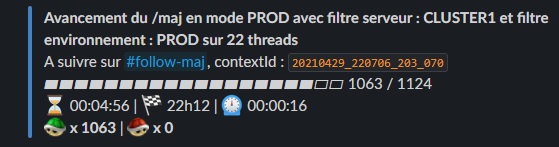
Here’s a monolith schema change over 1000’s databases per cluster, for a single cluster, reported live on a slack channel :
Today, each application is in a dedicated schema. We implement Conway’s law at the schema level : each team is responsible for managing it. So for Figgo - our leave management app - a table is [Figgo].[LeavePeriods].
But this has not always been the case : in the old monolith times, everything was on the [dbo] schema. So for some legacy tables, we are using SQL Views from an app schema to “simulate” isolation against an “out of domain” table. It's an assumed shortcut for helping the monolith migration.
There’s an underlying important consideration here : we are trying delete every low level coupling factor between apps, but we don’t strictly forbid them, because ATM, we miss some critical part to achieve a complete isolation, like some kind of eventually consistent data replication between domains. That’s another WIP subject for the next years.
Anatomy of a SQL instance
A typical SQL instance at Lucca is on SQL Server 2019, Standard Edition CU9, and has between 8 and 20 cores depending on the cluster actual load.
All the SQL Instances are running under Windows Server 2019, with at least a 2 socket NUMA configuration. We have had a real NUMA performance issue with vSphere and Windows Server 2016, that took months to identify (it was the windows version) and fix. So now, win2k19 is our baseline.
Each SQL instance coexists with:
- a replica, having only databases in restoring mode
- a dedicated “backup VM” : all the backups are made to a VM
- a PRA VM (Plan de reprise d’activité = DR, or Business Continuity Management), also restoring logs in continuous mode.
So just for the SQL part of a cluster, we have 4 virtual machines. All VM are on distinct fault domains, with the exception of the PRA ones, which are in a distant datacenter.
Why didn’t we go with the Enterprise Edition ? Because of the price tag versus the few features we could leverage in our specific case.
- We don’t have page life expectancy issues (this metric keeps growing until the weekly index rebuild), so the 128Gb allocated to each instance is enough.
- We just can’t use the Availability Groups feature with more than 1000 databases. SQL Server AGs aren’t tailored for such cases.
- We would certainly be happy to use the online index rebuild, or the batch mode memory grant feedback, but is it really worth the cost of the Enterprise vs Standard edition ? clearly nope.
Our current volume challenges
As of October 2021, just for production, we have ~5000 tenants in 6 clusters in our OVH-Roubaix datacenter, and less than 100 in our Swiss datacenter.
We also have 5500 demo instances, 4500 training instances (formation), and around 1000 preview instances. These are not production ones, and aren’t currently backed up in a distant zone, because we accept to lose these non production ephemeral instances.
One of the main challenges with this high number of databases is keeping our RPO low. And that’s not an easy challenge.
Before the last OVH incident in Strasbourg (a datacenter burned), we were doing hourly backups, and daily uploads to an Azure blob storage. Since this incident, we have changed our policy to a 10min RPO. This means every 10 minutes, every database has a backup LOG made, this backup is restored on both replicas (the on-site replica, and the distant one), and this backup is sent to Azure blob storage.
Historically, we were using Brentozar’s script to both backup and restore. But despite some optimizations on the restore side, we struggled to achieve our 10min RPO target. So we’ve developed a little dotnet tool (https://github.com/LuccaSA/SqlBackupTools) to restore LOG files in parallel, with the best possible efficiency. This tool runs on the replicas (with SQL agent scheduled task), and reports all potential problems (like RPO outliers) on a slack channel. (we massively use slack bots for everything, and that’s a real pleasure)
However, we still have a pain in the neck on the backup side. We still use the ola hallengren backup stored procedure, every 10 min, and this is causing spikes in CPU (up to 20%), because of the design of this stored procedure : sequentially backup all the databases.
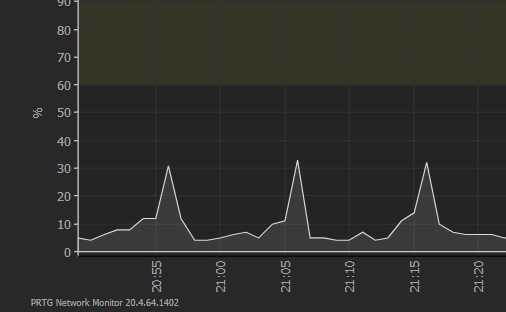
So the current plan for the coming months, is to implement the backup operation in SqlBackupTools, in order to spread the backup operations over the 10 min time frame, instead of backing them up as fast as possible, do nothing and then wait until the next execution.
Our applicative SQL challenges
The first and most offending pain point is our legacy code base and the associated performance impact on the SQL side. This is largely due to a legacy framework, which permits API sub-resources exposition, and manages a major part of SQL queries via ExpressionTree manipulation.
On one side, it has let us do highly generic things, like creating a generic permission filter to apply on any table, but on the other side, this produces really hard to debug and hard to optimize SQL queries.
Another consequence of using EF6 massively, are the really underperforming queries generated, specifically around UNION ALL and ORDER BY clauses. We do have some developers dreaming of using Dapper, but adoption hasn't started massively yet. The same goes for stored procedures usage, but this is evolving, little by little.
Other current performance pain points are architectural ones, once again from legacy code. Let’s describe two examples :
We have a reminder service (to show reminder toasts on the home page), which makes calls to every soft, and every soft makes a lot of queries to just retrieve a few values. One possible plan is to reverse the dependency, and just let the apps push their notifications to a “reminder service”. And then this service could easily just retrieve plain data in a fast way.
Another pain point was our
Departmentmodel (a simple hierarchy), which was modeled in a strange ascii based specific way. (deserving a blog post). The main point here was the impossibility to easily make SQL queries against this hierarchy without loading all the departments in .NET memory. The consequence was we can’t evaluate user's permissions over departments without this hierarchy, and almost every permission filter results in a list of users Ids on the C# side, producing queries with huge IN Clauses. (we use the STRING_SPLIT() method in our .NET Core apps, but still have no way to use it with EF6). We recently migrated thisDepartmenttable toHierarchyId, resulting in strong perf gains, and hope to try SQL calculated permissions soon.
Some of our major SQL outages
Dropping a production cluster
The crime scene takes place in 2018, on February 21st. At that time, we were still having dedicated VMs for both SQL and IIS (so before the cluster), and at that time, we were just not having replicas.
After exhausting weeks, one of our colleagues, on a non production VM (a test VM), launched SSMS, in order to clean up and drop all the databases.
Unfortunately, SSMS connection popup was preselected with a production server, and after clicking “Connect” without looking at the content, he just dropped all the databases on the SQL Instance.
Last backups at this time were from the day before, so more than 16h data loss. Fortunately, we were using SAN storage at this time, and OVH (our hosting provider) is using ZFS on these. So we just restored the last snapshot, with less than 1h data loss. It’s in these hard times we can see the real DNA of a company, and that day, everyone was onboard, from consultants to developers in order to help reduce the data loss to its minimum. We explored all the logs, deduced all the lost end-user actions, contacted each customer, and a day later, everything was back.
This outage is the reason of this stored procedure :
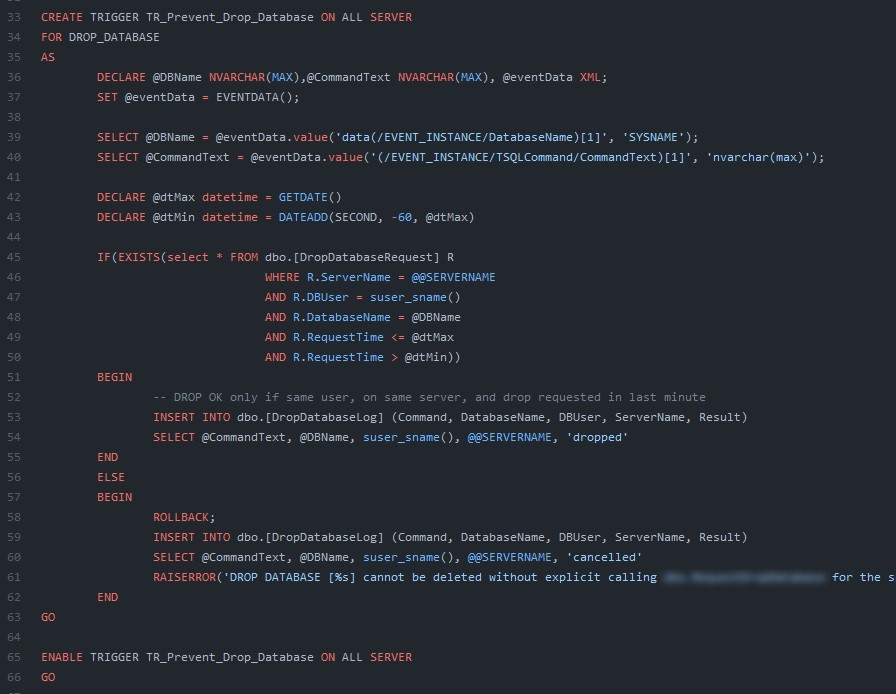
Imploding a SQL VM
Last year, in august, we had a major outage on our vSphere servers : a VM, a SQL Instance, just froze. Simply froze, nothing possible : couldn’t stop the VM, couldn’t restart it, nothing. Even restarting the host was impossible. No other VM was impacted, but this one, a primary SQL one was stuck.
The hard part is all backups were on the VM itself, not on another VM, and the replica was out of sync (daily sync at that time). If only we could have had access to the backup, we could have restored the DB on the replica, but no, impossible. So we learned the hard way : never backup on the same VM, and always have a ready replica.
In order to workaround this problem, we need to manually copy the vmdk, and then recreate a new VM while importing the vmdk copies. Easy once we know how to workaround :)
After spending the night on this, and solving the issue at 5am, one important thing we learned the next day, is our customers prefer an 11h outage with no service over any data loss.
This issue has escalated to the OVH’s CEO, CTO, and to the VMWare expert support team. Technically, what happened is a mix of a NTP time desynchronization on a single host (5h), and a vmotion to another host with memory ballooning leading to a swap error, leading to an incoherent internal state. Only two customers experienced such an issue worldwide.
We are one of them.
Bad execution plan
It happens, once in a while, that a query plan generates a real problem. This is what happened on a Monday morning, with an actual customer on an actual software : our web requests started to take an impressive amount of time, and this behavior was accumulating over time.
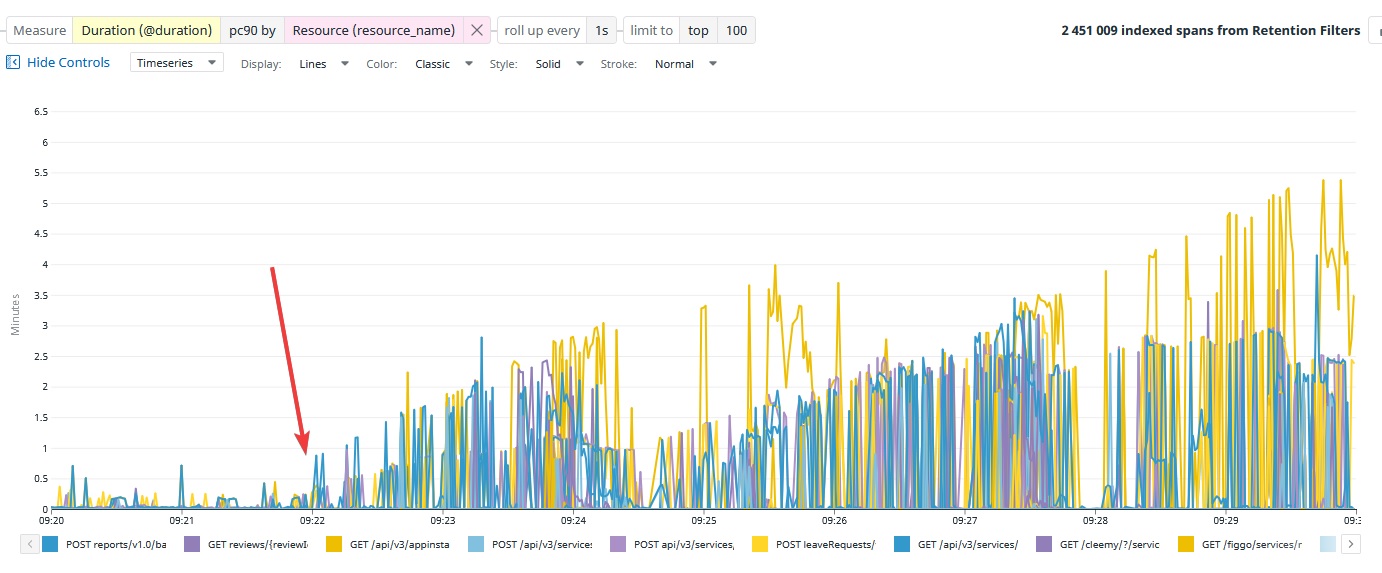
When long SQL queries using a lot of CPU slows everything, that's how API response time behaves : a beautiful saw-tooth latency graph.
What happened is an actual fuzzy search call (in a search box), started to generate wrong execution plans, resulting in a cumulated CPU saturation on our SQL Instances.
Spotting the root cause is hard in this case : all the db operations start to have high durations, and there’s no recent schema change, just a different way of using an existing query. There’s also misleading clues, like this BrentOzar sp_Blitz report about RESOURCE_SEMAPHORE_QUERY_COMPILE poison wait..
What helped a lot in this case is have the QueryStore activated on the victim database, and having put this cluster in maintenance mode, and then reopened it, so we have had a little calm period to do a full trace while trafic ramps up, and identify the injuring query easily : it was taking 30 seconds.
We've had a 1h outage, with one cluster suffering really degraded performances. The fix has been to rewrite the dotnet code to generate a different query plan.
We since added Datadog’s APM alerts on every SQL queries longer than 5 seconds.
Full text indexes
There are two functional cases where we are using a fuzzy search : user pickers, and axis section pickers. We don’t have an Elasticsearch instance (yet?) in our infrastructure, since full text indexes fulfill all our current needs, with correct latencies.
However, FT indexes looks like an “added feature” in SQL Server, like something plugged later as an additional plugin, rather than something built-in from scratch into the code. Indexing behavior is specific, and methods to deal with them are far from native indexes.
We discovered this the hard way.
2 times…
First time, we added just simply too many FT indexes to the same catalog. We discovered there’s a limit, which is clearly documented by microsoft.
When adding the “over the limit” FT index, the SQL Instance simply stopped responding. A lot of log files are generated in the SQL log folder, main external symptom of the issue. The only way to restore a functional state, is to restart the instance, and drop the added index as fast as possible.
Second time, while deploying a new app version in production, containing a schema migration with a new FT index, the SQL Instance just stopped responding. CPU at 3~5%, but unresponsive. FT index creation is not a blocking operation : if we run a CREATE FULLTEXT INDEX ON .. statement, SQL Server just “queues” the command, and returns instantaneously. And there’s a fact, this is maybe a “queue” from a single db point of view, but not a real queue for multiple dbs, this is more like a “spawn a new concurrent thread”. How did we deduce that ? Hundreds and hundreds of “Crawl Started” messages in SSMS profiler.
In most cases, this runs without problems for everyone on earth. But at Lucca, we have a lot of databases per instance, up to 7000 db on the demo cluster. And queuing so many FT indexing requests, just blows up the SQL instance.
So how do we deal with this ? We created a stored procedure, blocking the caller until all FT operations are finished on the current db. And we limit the number of parallel database schema modifications while deploying.
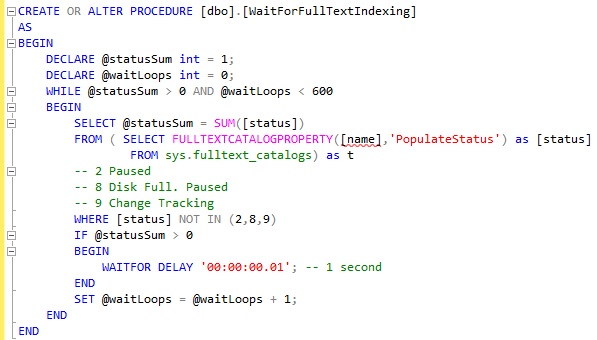
Since we both enforced the maximum number of FT index per catalog, AND waited explicitly for FT indexing, we didn’t have any new FT related outage.
Actual limitations
Our current tenancy model (1 db per tenant), as any model, has advantages and drawbacks.
First major drawback, SQL Server Availability Groups are just impossible with so many databases. Microsoft doesn’t have an internal limit, but the operational maximum is around 100 databases per instance.
So we have an aggressive log shipping strategy, and with recent RPO decrease to 10 minutes, we are starting to see a light performance impact on the primary database when using Hallengren's DatabaseBackup stored procedure. On the other side (on the replica), we are restoring LOGs in parallel, so every 10 minutes, the guest consumes a lot of CPU on the host.
There’s interesting optimizations opportunities worth exploring on the backup side, like spreading individual backup operations over the 10 minutes time frame, and letting replicas know new TRN files are available by pushing events, rather than blindly scraping folders every 10 minutes.
Second drawback, there’s some hard limits in SQL Server. We are pretty comfortable with CPU / RAM limits on the SQL standard edition, but the maximum 32k active connection limit is a hard one. We have on each cluster, 6 net471 app pools, and 44 (22x2) .NET Core app pools. If you multiply this by 1000 tenants, we could theoretically hit this hard limit if every tenant is making a web-request on all apps at the same time. In practice, this "statistically never happens".
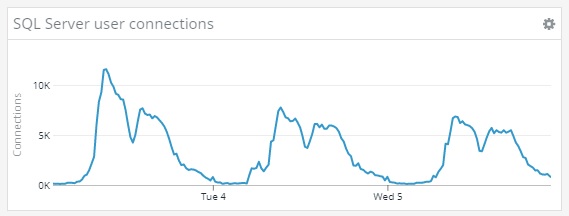
At peak load on Monday mornings, we actually have around 11k active user connections mostly due to SqlConnection pooling. At the same time, we have at most around 60 concurrent queries executing, and the SQL Instance handles 3300 requests / sec.
So this is a real design issue, both on our side (having a shared database between apps of each tenant), and on the SqlConnection pooling side (keeping every connection in the pool active for an unconfigurable duration). And as the number of apps will increase, this metric will also increase.
So what are solutions ?
- Split each tenant database per app, on separated SQL instances.
- Stop using pooling, and pay the handshake price for each SQL request
- Reduce the number of tenant per cluster (the easiest fix)
- Wait for the next generation of Ado.Net in .NET Core and hope for a solution
- Hope for an hypothetical open source TDS proxy
There’s no easy root cause fix. ATM, we monitor this metric closely.
Third current major drawback : our file management. We are storing and delivering customer files from network shared block storages (DFS servers), and managing more than 2Tb of little files is a problem from a backup oriented perspective.
Back in 2017, we were using dedicated software to weekly backup our data on Azure, but a single backup operation was taking 6 days. And then, one day, backups started taking more than 7 days, and there’s no more than 7 days in a week. You deduce the rest of the story.
So we developed a custom tool (https://github.com/LuccaSA/TarCompressCrypt) which basically pipe 3 commands : a tar | zstd | openssl. Tar for packaging, Zstd for efficient compression, and openssl for encryption.
Running this operation for each tenant in a parallel way enables us to backup a whole cluster in 6 hours in 2018, and in 2 hours today. For incremental backups, we just say to the tar command to filter out files since the last diff backup. And we now achieve a 20 minute RPO on our DFS servers.
Why didn’t we use S3 like object storage instead and do off site live replication ? Because OVH don't have a solid object storage ATM, and only recently ISO 27001 certified it. On the other side, open source solutions like MinIO only started to get mature recently. So S3-like store is definitely something on our future roadmap.
Closing note on scalability
We are a scaleup company, and despite having no “VC boost”, we are growing at a strong rate. With actual projections, we could have, by the end of 2025, between 25k and 45k tenants on our infrastructure (depending the average tenant size).
With our actual “Cluster model" (1k customers per cluster), we can achieve these numbers from an architectural point of view. Our current limiting factor on the infrastructure side is our public bandwidth for continuous backup operations, and we can still add 3 clusters to our current zone before being “near the limit”. Then, we'll have to add another zone, to replicate this pattern, again and again. One interesting detail about OVH’s infrastructure is the VRACK : a private unlimited SDN, accessible from any service, so we can see and manage these multiple zones with a single internal network infrastructure.
If this current cluster model seems scalable, we also have a lot of challenges managing such an infrastructure, so we are actively looking at other options on the table for the next few years (Kubernetes, I look at you), while keeping in mind we need simple solutions for specific needs.
Other related articles
About the author
