Un peu de contexte
Figgo, notre logiciel de gestion d'absences, a 15 ans et a donc de la dette technique (dont du vieil ASP). Nous avons entrepris depuis bientôt 3 ans une politique de refactoring pour migrer tous nos vieux modules vers nos nouvelles technos/archi (.NET Core, Angular). Le module de régularisation en faisait partie.
La régularisation, ce sont des règles qui permettent de diminuer des congés acquis en fonction de conditions particulières. Par exemple :
Au-delà de 20 jours ouvrés consécutifs de congés maladie, on retire des congés payés au prorata de l'absence.
Imaginons qu'un utilisateur soit en arrêt maladie depuis le 01/01/2021 et que son arrêt se termine le 21/02/2021, alors on va pouvoir faire le calcul suivant :
- Premier jour au-delà du seuil : 01/02/2021 car janvier 2021 a exactement 20 jours ouvrés (le 01/01 est férié)
- Nombre de jours ouvrés en février 2021 : 20
- Nombre de jours ouvrés en en congés maladie : 15
- Ratio d'absence sur le mois : 15/20 = 0.75
- Nombre de jours de congés payés acquis sur février 2021 : 2.08
- Nombre de jours à régulariser : 2.08 * 0.75 = 1.56 On va donc retirer 1.56 congés payés sur février 2021 pour cet utilisateur.

Cet exemple est plutôt simple par rapport à la réalité car on peut agir sur un grand nombre de paramètres pour le calcul de la régularisation :
- Type de période de calcul (3 types différents)
- Seuil
- Plafond
- Consécutivité ou non du seuil/plafond
- Méthode de calcul du seuil (3 types différents)
- Type de calcul de régul
- Au prorata
- Mode de calcul (ouvré, ouvrable, calendaire, trentième)
- Par tranche
- Nombre de jours dans une tranche
- Unité
- Montant à retirer par tranche
- Au prorata
Et tout cela ne permet que de décrire une règle, son calcul est aussi dépendant des congés existants, des jours non travaillés, du cycle de travail (temps partiel, temps plein...), de l'acquisition et des éventuelles régularisations existantes... Bref la complexité explose et tous ces paramètres sont interdépendants, de quoi s'arracher quelques cheveux.
Il nous semblait évident de faire des tests automatisés pour tout ça. Cependant, utiliser des tests unitaires standards avec xUnit aurait vite fait d'atteindre nos limites car le code n'aurait pas été très clair à comprendre en raison des grosses phases d'Arrange pour créer le contexte de test, à moins de faire quelques builders. Un autre aspect important était de gérer cette combinatoire de façon simple.
C'est pour ces raisons qu'on s'est tourné vers SpecFlow.
SpecFlow
SpecFlow est une librairie de BDD qui permet d'écrire des tests au format Gherkin. Pour faire des tests avec SpecFlow, il faut 2 types de fichiers :
- Des fichiers
.featurequi contiennent les tests au formatGherkin - Des fichiers de steps en
C#
Prenons cet exemple trivial, on aura donc un fichier .feature :
Feature: Addition
Scenario: 1 + 2 = 3
Given a first number 1
And a second number 2
When we add them
Then it should return 3Une Feature permet de regrouper des Scenario qui correspondent chacun à un cas de test. Chaque Scenario est composé de Step qui sont de 3 types possibles :
Givenpour la phase d'Arrange, c'est-à-dire la préparation des données.Whenpour la phase d'Action, qui déclenche le comportement à tester.Thenpour la phase d'Assert, pour vérifier le comportement exécuté.
Il faut un fichier de steps pour câbler ces Step avec du code C# :
[Binding]
public class AdditionSteps
{
private int _actual, _first, _second;
[Given(@"a first number (\d+)")]
public void GivenFirstNumber(int first) =>
_first = first;
[Given(@"a second number (\d+)")]
public void GivenSecondNumber(int second) =>
_second = second;
[When(@"we add them")]
public void WhenWeAddThem() =>
_actual = _first + _second;
[Then(@"it should return (\d+)")]
public void ThenItShouldReturn(int expected) =>
Assert.Equals(expected, _actual);
}Une classe de steps consiste simplement en une classe pourvue d'un attribut [Binding], où sont présentes des méthodes de steps décorées d'un attribut [Given], [When] ou [Then]. Ces attributs permettent d'identifier la bonne phrase et de capturer des valeurs à l'emplacement des parenthèses (exemple (\d+) pour récupérer un nombre).
Ce code fonctionne parfaitement, mais il est déconseillé de faire comme ça.
En effet, tous les steps sont accessibles dans TOUT le projet de tests et donc on va vite avoir besoin de travailler sur une même valeur dans plusieurs classes de steps. SpecFlow permet de se faire injecter des contextes, qui sont simplement des classes avec une durée de vie au scénario.
L'exemple précédent réécrit avec un contexte donnera le code suivant :
public class AdditionContext
{
public int First { get; set; }
public int Second { get; set; }
public int Actual { get; set; }
}
[Binding]
public class AdditionSteps
{
private readonly AdditionContext _context;
public AdditionSteps(AdditionContext context) =>
_context = context;
[Given(@"a first number (\d+)")]
public void GivenFirstNumber(int first) =>
_context.First = first;
[Given(@"a second number (\d+)")]
public void GivenSecondNumber(int second) =>
_context.Second = second;
[When(@"we add them")]
public void WhenWeAddThem() =>
_context.Actual = _context.First + _context.Second;
[Then(@"it should return (\d+)")]
public void ThenItShouldReturn(int expected) =>
Assert.Equals(expected, _context.Actual);
}L'avantage de cette approche, c'est qu'on va pouvoir récupérer les valeurs qui se trouvent dans AdditionContext depuis n'importe quelle classe de Step.
SpecFlow pour les régularisations
Le calcul de régularisation est vaste mais peut se distinguer en trois grosses parties :
- La définition des informations d'une règle de régularisation
- La création du contexte d'exécution contenant toutes les absences, les acquisitions et les régularisations existantes
- Le calcul et l'exploitation de son résultat
Si on veut tester la règle précédente
Au-delà de 20 jours ouvrés consécutifs de congés maladie, on retire des congés payés au prorata de l'absence.
sur un congé maladie du 01/02/2021 au 21/02/2021, on écrira le .feature suivant :
Feature: Prorata in business days
Background:
Given a prorata adjustment rule working on business days
And a calculation period between 01/02/2021 and 28/02/2021
And with impacting accounts
| AccountId | AccountName |
| 2 | Maladie |
Scenario: With threshold
Given there are leaves periods like
| AccountId | Start | End |
| 2 | 01/01/2021 | 21/02/2021 |
And with 20 business days consecutive threshold
When calculation is executed
Then the amount should be -1.56
And the code should be "REGUL"
And there should be these metrics
| Code | Value |
| AlreadyAcquiredAmount | 2.08 |
| ImpactingLeaveDays | 15 |
| TheoricalDaysCount | 20 |
| TheoreticalAdjustedRate | 0.75 |
| NewAdjustmentAmount | -1.56 |Background permet de jouer des steps à chaque exécution de Scenario, ce qui permet de limiter la taille de ces derniers en se concentrant uniquement sur ce qui va varier.
On ne se contente pas juste de calculer la régularisation à appliquer, on veut aussi pouvoir détailler le calcul :

C'est à ça que servent les métriques. Elles sont calculées lors de l'exécution du calcul et renvoyées dans les informations de résultat.
En termes d'organisation du code, on aura cette arborescence :
- Tests
- Contexts
- AdjustmentRuleContext
- ExecutionContext
- CalculationContext
- Steps
- AdjustmentRuleSteps
- a prorata adjustment rule working on business days
- a calculation period between 01/02/2021 and 28/02/2021
- with impacting accounts
- with 21 business days consecutive threshold
- ExecutionSteps
- there are leaves periods like
- CalculationSteps
- calculation is executed
- the amount should be -1.56
- the code should be "REGUL"
- there should be these metricsLe step de période de calcul sera donc implémenté comme ceci :
public class AdjustmentRuleContext
{
public CalculationPeriod CalculationPeriod { get; set; }
// ...
}
[Binding]
public class AccrualRuleSteps
{
private readonly AdjustmentRuleContext _adjustmentRuleContext;
public AccrualRuleSteps(AdjustmentRuleContext adjustmentRuleContext) =>
_adjustmentRuleContext = adjustmentRuleContext;
[Given(@"calculation period is between (.*) and (.*)")]
public void GivenCalculationPeriodIsBetween(DateTime startDate, DateTime endDate) =>
_adjustmentRuleContext.CalculationPeriod = new CustomCalculationPeriod(startDate, endDate);
// ...Tout comme dans l'exemple de l'addition, SpecFlow permet de convertir automatiquement les valeurs capturées par la regex vers le type attendu par le paramètre. Il y a plusieurs conversions déjà implémentées, mais on peut aussi rajouter des converters pour des besoins précis via les IValueRetriever.
Les Table font partie des mécaniques puissantes de SpecFlow. Elles permettent d'exprimer facilement des collections d'objets :
public class TestLeavePeriod
{
public int AccountId { get; set; }
public DateTime Start { get; set; }
public DateTime End { get; set; }
public Period Period => new Period(Start, End);
}
public class ExecutionContext
{
public IReadOnlyCollection<TestLeavePeriod> LeavePeriods { get; set; }
// ...
}
[Binding]
public class ExecutionSteps
{
private readonly ExecutionContext _executionContext;
public ExecutionSteps(ExecutionContext executionContext) =>
_executionContext = executionContext;
[Given("there's leaves periods like")]
public void GivenTheresLeavesOnAllPeriod(Table table) =>
_executionContext.LeavePeriods = table.CreateSet<TestLeavePeriod>().ToList();
// ...
}Le gros avantage des Table c'est qu'on peut établir leur structure en fonction de ce qui est le plus lisible pour le test. Ce point est très important pour avoir des tests simples à lire tout en permettant d'exprimer un maximum de cas.
Ce n'est que lorsque l'on en aura besoin que l'on transformera les objets de tests en objets du domaine. Par exemple, on a besoin des LeavePeriod (ce qui permet de représenter une période d'absence) uniquement lors de l'exécution du calcul :
public class CalculationContext
{
private readonly AdjustmentRuleContext _ruleContext;
private readonly ExecutionContext _executionContext;
public CalculationContext(
AdjustmentRuleContext ruleContext,
ExecutionContext executionContext)
{
_ruleContext = ruleContext;
_executionContext = executionContext;
}
public CalculationResult ActualCalculationResult { get; set; }
public void Calculate()
{
// Convert test objects to domain objects
var leavePeriods =
_executionContext.LeavePeriods
.Select(lp => new LeavePeriod(lp.Period, lp.AccountId, userId: 1))
.ToList();
// Calculation
ActualCalculationResult =
AdjustmentCalculation.Calculate(
_ruleContext.BuildRule(),
leavePeriods);
}
}
[Binding]
public class CalculationSteps
{
private readonly CalculationContext _calculation;
public CalculationSteps(CalculationContext calculation) =>
_calculation = calculation;
[When(@"calculation is executed")]
public void WhenFixedAccrualIsExecuted() =>
_calculation.Calculate();
[Then(@"the amount should be (.*)")]
public void ThenTheAmountShouldBe(decimal expectedAmount) =>
Assert.Equal(expectedAmount, _calculation.ActualCalculationResult.Amount);
// ...
}Il y aurait beaucoup de choses à montrer sur les tests des régularisations, mais on a vu ici les aspects les plus importants.
Conclusion
Pour les régularisations
Personne dans l'équipe n'avait eu l'occasion de travailler sur SpecFlow avant ce projet. La phase de découverte de la librairie et de la syntaxe Gherkin passée, les développeurs sont devenus autonomes en moins d'une semaine et ont pu assez rapidement avoir suffisamment de Step pour pouvoir couvrir les différents Scenario à tester.
Le gros point fort de SpecFlow, c'est la lisibilité des tests. Notre métier est assez complexe et avoir des tests clairs qui servent aussi de documentation est un très gros plus, pour ceux qui ont codé les tests, mais aussi pour les autres membres de l'équipe qui découvriront le module plus tard lors d'un nouveau cycle de développement. Une conséquence de cette lisibilité, c'est que les Product Owners sont capables de comprendre plus facilement ces tests et ont été capables de nous montrer des erreurs dans ces derniers.
SpecFlow est aussi très paramétrable. À partir du moment où on a un Step, on va pouvoir facilement faire varier certaines valeurs. On peut les faire varier au sein d'un Step ou via l'utilisation d'une Table, mais aussi grâce au Scenario Outline qui permet d'exécuter plusieurs fois le même test en faisant varier quelques valeurs :
Feature: Addition
Scenario Outline: 1 + n = n + 1
Given a first number 1
And a second number <n>
When we add them
Then it should return <expected>
Examples:
| n | expected |
| 3 | 4 |
| 11 | 12 |
| 100 | 101 |Ce sont ces mécanismes qui font que la combinatoire a été gérée aisément, on code quelques Step et on ouvre une grande possibilité de Scenario supplémentaires. Toutes ces mécaniques sont aussi présentes dans les frameworks de tests comme xUnit, SpecFlow permet juste de les exprimer de façon plus claire et concise.
Pour tempérer un peu les points précédents, SpecFlow est plus compliqué à mettre en place que de simples tests via xUnit. En effet, il faut penser, entre autres, à :
- correctement séparer les fichiers de
Step - correctement séparer les fichiers de contexte
- limiter l'interdépendance entre les
Step
D'où une frustration sur le fait que le projet de tests devient un projet avec une maintenance assez importante. Il faut souvent réorganiser ses fichiers, refactorer le code des Step ou de contextes pour éviter d'avoir du code spaghetti, bref se poser des questions d'architecture.
Au-delà des régularisations
Actuellement, on utilise SpecFlow dans d'autres projets mais on ne l'a pas systématisé. Notre guideline pour SpecFlow c'est de l'utiliser si :
- il y a une forte combinatoire dans ce qu'on veut tester
- on veut des tests clairs et compréhensibles par des Product Owners
Pour des tests très unitaires, on privilégie xUnit. Pour ce qui est plus haut dans la pyramide de tests, SpecFlow est assez adapté.
Pour aller plus loin, il existe la living documentation qui permet de générer un rapport lors d'un build Jenkins. Ce qui est appréciable avec ce rapport, c'est de voir rapidement quels tests ne passent pas et surtout à quel Step.
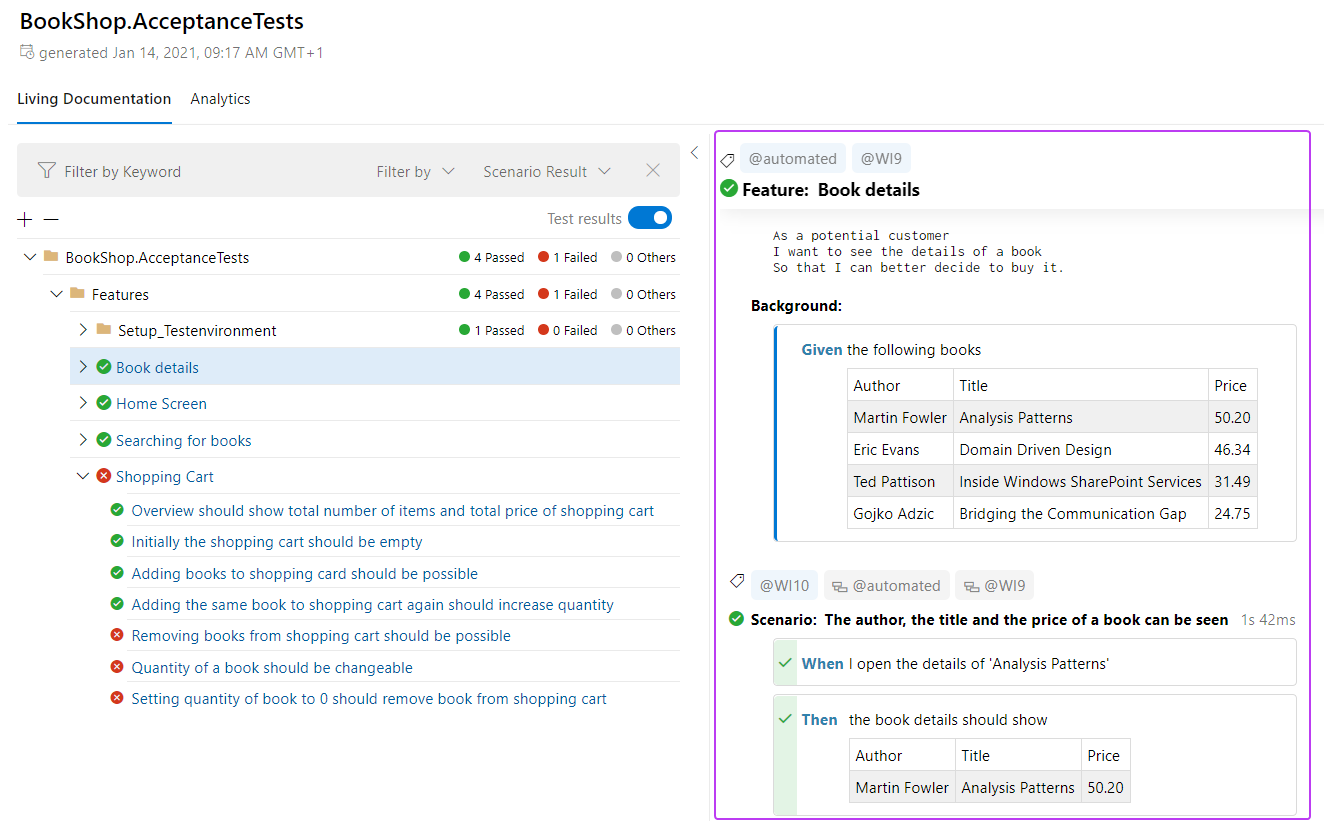
Une autre utilisation de SpecFlow bien développée, y compris en dehors de notre équipe produit, concerne les tests d'API. L'idée est de tester nos routes directement via des appels HTTP, le tout câblé sur une base de données locale générée lors du test.
# language: en-GB
@ProrataAdjustmentSimulation
Feature: Simulate Prorata Adjustment Rules
Scenario: Simulate Prorata Adjustment Rule
Given Daniel Hernandez as principal
And some leaves
| OwnerId | AccountId | Year | Month | Days |
| 2 | 1 | 2020 | 11 | 2;3 |
| 3 | 1 | 2020 | 11 | 2 |
When http POST /statutories/v1.0/1/accrualRules/1/simulations with body
"""
{
"rangeStart": "2020-10-01",
"rangeEnd": "2020-10-31",
"explainCalculation": false,
"userIds": []
}
"""
Then the http status is 200
And the json content contains these metrics
| Code | Value |
| AlreadyAcquiredAmount | 2,08 |
| AlreadyAdjustedAmount | 0 |
| ImpactingLeaveDays | 0 |
| TheoricalDaysCount | 31 |
| TheoreticalAdjustedRate | 1 |
| TheoreticalAdjustedAmount | 2,08 |
| NewAdjustmentAmount | 0 |
L'exécution est assez longue mais ça permet de faire des tests assez fiables qui vont tester les requêtes de l'ORM, la sérialisation, les droits, etc. En temps normal, l'assertion se fait sur le JSON complet qui doit être renvoyé, mais on peut aussi rajouter nos propres steps pour tester uniquement ce qui nous intéresse tout en rendant le test moins lourd.
Dernier étage de la pyramide de tests, les tests End-To-End. Nous avons toute une batterie de tests QA qui remplacent l'ancienne recette manuelle qui était faite tous les mercredis par les Product Owners. Ces tests sont écrits avec xUnit, Selenium et quelques helpers pour simplifier l'écriture des tests. On pourrait tout aussi bien utiliser SpecFlow qui est très adapté dans les tests End-To-End (quelle que soit la technologie utilisée).
Pour creuser SpecFlow, on vous encourage à lire leur documentation qui est simple et détaillée.
About the author
